Paper Links
Abstract
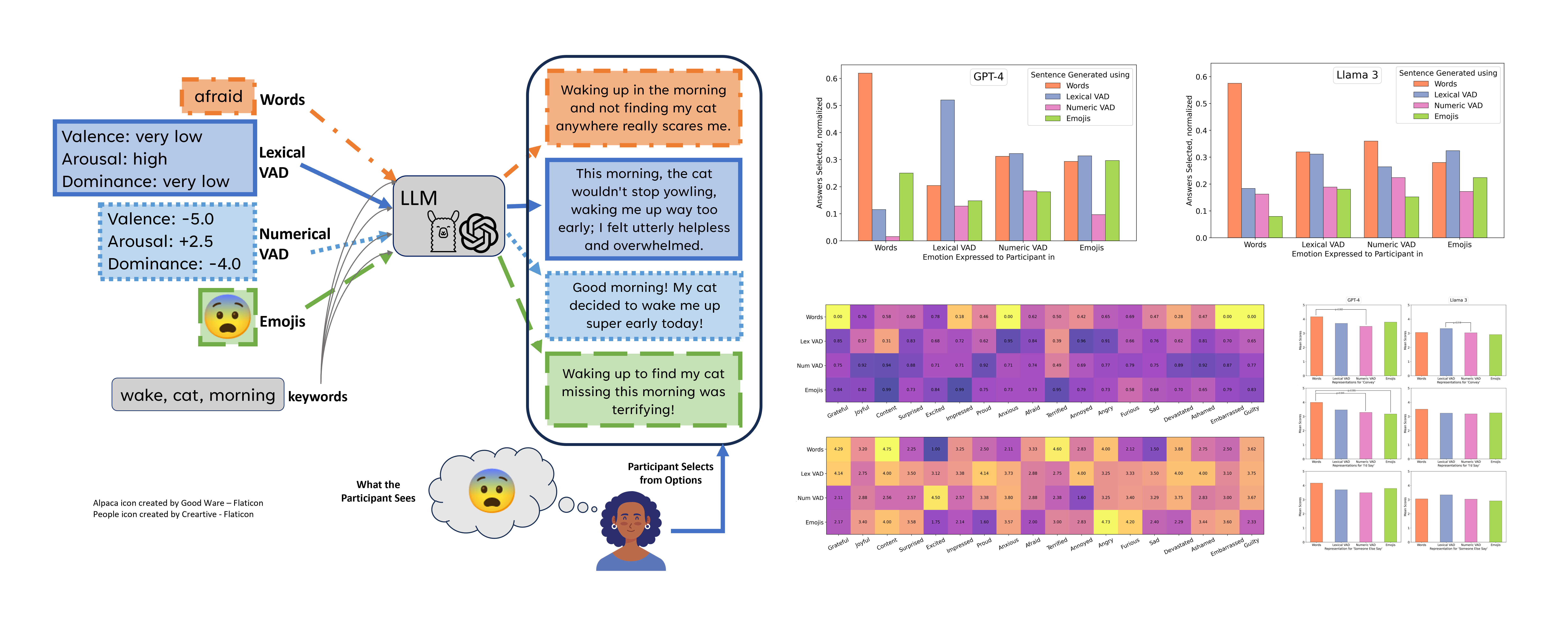
Gaps arise between a language model’s use of concepts and people’s expectations. This gap is critical when LLMs generate text to help people communicate via Augmentative and Alternative Communication (AAC) tools. In this work, we introduce the evaluation task of Representation Alignment for measuring this gap via human judgment. In our study, we expand keywords and emotion representations into full sentences. We select four emotion representations: Words, Valence-Arousal-Dominance (VAD) dimensions expressed in both Lexical and Numeric forms, and Emojis. In addition to Representation Alignment, we also measure people’s judgments of the accuracy and realism of the generated sentences. While representations like VAD break emotions into easy-to-compute components, our findings show that people agree more with how LLMs generate when conditioned on English words (e.g., “angry”) rather than VAD scales. This difference is especially visible when comparing Numeric VAD to words. Furthermore, we found that the perception of how much a generated sentence conveys an emotion is dependent on both the representation type and which emotion it is.
Code
Credits
Shadab Hafiz Choudhury 1 3, Asha Kumar 2, Dr. Lara J. Martin 1 3
1: Department of Computer Science and Electrical Engineering, University of Maryland, Baltimore County
2: Department of Information Systems, University of Maryland, Baltimore County
3: Corresponding Authors
Citation
@inproceedings{choudhury2025evaluatingHuman-LLM,
address = {Mumbai, India},
title = {Evaluating Human-LLM Representation Alignment: A Case Study on Affective Sentence Generation for Augmentative and Alternative Communication},
shorttitle = {Evaluating Human-LLM Representation Alignment},
booktitle = {Findings of the {Association} for {Computational} {Linguistics}: {IJCNLP}-{AACL} 2025 ({Findings})},
author={Shadab Choudhury and Asha Kumar and Lara J. Martin},
month = dec,
year={2025},
}